AI,
Ideas,
the Future of Research
Fatih Kansoy
University of Oxford
Lecture
Outline
Today
The talk
in six parts.
in six parts.
Ideas, old gates, automation, agents, research workflows, and one practical pipeline.
01
Ideas Matter, Always
History, capital, and the central place of ideas.
02
The Old Gates
Knowledge, access, faster answers, and the new scarcity.
03
From Assistance to Automation
ANI, AI-generated papers, and the Nature case.
04
From Chatbox to Agents
Skills, agents, orchestration, and pipelines.
05
From Questions to Workflows
API-scale research and two concrete examples.
06
Practice
One question, one pipeline, one live research workflow.
Fatih Kansoy
University of Oxford
02
Section
01
01
Ideas Matter,
Always.
Always.
History • Capital • Ideas
Fatih Kansoy
University of Oxford
02
Section 01
Ideas Matter, Always
A long time ago in a galaxy far, far away....
Fatih Kansoy
University of Oxford
03
Section 01
Ideas Matter, Always
No Industry Without Order
Leviathan
"
Whatsoever therefore is consequent to a time of Warre, where every man is Enemy to every man... [there is] no place for Industry... no Society; and which is worst of all, continually feare, and danger of violent death; And the life of man, solitary, poor, nasty, brutish, and short.
Hobbes’s point: before growth, trade, or innovation, society needs order. Security is the precondition for industry.

Thomas Hobbes
Leviathan · 1651
Fatih Kansoy
University of Oxford
04
Section 01
Ideas Matter, Always
A Growth Story: Solow, Romer, and Jones
Solow
Focus
Physical Capital
Output rises through capital deepening, but each extra unit of capital adds less than the one before.
Romer
Focus
Ideas
Ideas are produced inside the economy and can be used by many people without being used up.
Jones
Focus
Ideas Harder
As the frontier moves out, more researchers are needed to sustain the same pace of idea creation.
Fatih Kansoy
University of Oxford
05
Section 01
Ideas Matter, Always
A Growth Story · 1 of 3
Solow
Focus: Physical Capital
Output rises through capital deepening, but each extra unit of capital adds less than the one before.
Fatih Kansoy
University of Oxford
05
Section 01
Ideas Matter, Always
A Growth Story · 2 of 3
Romer
Focus: Ideas
Ideas are produced inside the economy and can be used by many people without being used up.
Fatih Kansoy
University of Oxford
05
Section 01
Ideas Matter, Always
A Growth Story · 3 of 3
Jones
Focus: Ideas Harder
As the frontier moves out, more researchers are needed to sustain the same pace of idea creation.
Fatih Kansoy
University of Oxford
05
Section 01
Ideas Matter, Always
“Everything has been invented”
E = mc²
F = ma
dP / dt
Patent Office
Filed 1899

Charles H. Duell
U.S. Commissioner of Patents
Commonly attributed, 1899
"
Everything that can be invented
has been invented.
has been invented.
The deeper lesson is not the quote itself. The mistake is perennial: each era keeps treating the limits of current imagination as the limits of invention.
Fatih Kansoy
University of Oxford
06
Section
02
02
The Old Gates
& The New Scarcity
& The New Scarcity
Chained books • The broken monopoly • Faster answers • The right question
Fatih Kansoy
University of Oxford
11
Section 02
The Old Gates

The Old Scarcity
Knowledge Was Gatekept
Before print and mass education, most people were excluded before they could even begin to read, think, or write.
01
Physical Access
Books were scarce, expensive, and often chained inside elite libraries.
02
Language
Scholarship lived in learned languages that most people could not access.
03
Institution
Universities, monasteries, and courts decided who could join the conversation at all.
Fatih Kansoy
University of Oxford
12
Section 02
The Old Gates
The Wall Starts To Crack
Breaking the Monopoly
As copying and distribution got cheaper, more people could read, learn, and contribute.
1450
Print
Books stop being aristocratic objects.
19th C.
Public Libraries
Reading moves beyond universities, courts, and monasteries.
1990s
Open Web
Papers and courses spread beyond the campus gate.
Now
AI Tools
AI lowers the cost of doing, not just reading.

Fatih Kansoy
University of Oxford
13
Section 02
The Old Gates
What changed
AI Makes Hard
Answers Faster
Answers Faster
For a long time, hard questions stalled because the search itself was too expensive. AI lowers that cost.
The shift
Curiosity did not change. The cost of reaching an answer did.
Before
Decades
Hard questions often just waited for enough search, enough data, or enough compute.
With AI
Search
Models sharply lower the cost of exploring structures, proofs, code, simulations, and candidate answers.
Result
Faster
Questions that once looked immovable start to become tractable much sooner than before.
Case: AlphaFold
50 years
Protein-structure prediction remained a stubborn problem for half a century.
A long-stalled problem started to move.
AlphaFold showed what happens when models, data, and compute line up: a hard scientific search problem becomes dramatically more tractable.
Models
Data
Compute
Fatih Kansoy
University of Oxford
14
Section 02
The Old Gates
The next break in scarcity
Answers Come
Faster
Faster
Search, drafting, coding, translation, and analysis are suddenly available to far more people than before.
Search
Draft
Code
Translate
Explain
Test
The old gate falls again: capabilities once reserved for expert teams and institutions now sit on ordinary machines.
What remains scarce
Can it ask
the right
question?
the right
question?
If AI helps us answer faster and better, the frontier may move toward judgment: which problem is worth pursuing, framing, and insisting on.
When answers get cheaper, taste, vision, and scientific judgment become more valuable, not less.
Fatih Kansoy
University of Oxford
15
Section
03
03
From Assistance
To Automation
To Automation
AI-assisted vs AI-generated • The AI Scientist • Milestones and limits
Fatih Kansoy
University of Oxford
08
Section 03
From Assistance to Automation
ANI, AGI, and ASI
Present
ANI
Artificial Narrow Intelligence
Built for bounded tasks. Fast, useful, and narrow.
Examples: ChatGPT, Siri, search, translation, recommendation.
Goal
AGI
Artificial General Intelligence
A system that could reason, learn, plan, and transfer knowledge across many domains.
Claim: not one workflow, but broad competence across tasks.
Hypothetical
ASI
Artificial Super Intelligence
A theoretical system that would exceed the best human minds across most or all relevant domains.
Status: speculative, debated, and not something that exists today.
Fatih Kansoy
University of Oxford
07
Section 03
From Assistance to Automation
AI Spectrum · 1 of 3
ANI
Present
ANI
Artificial Narrow Intelligence
Built for bounded tasks. Fast, useful, and narrow.
Examples: ChatGPT, Siri, search, translation, recommendation.
Today’s systems are already powerful, but they still operate as specialised tools, not general minds.
Fatih Kansoy
University of Oxford
00
Section 03
From Assistance to Automation
AI Spectrum · 2 of 3
AGI
Goal
AGI
Artificial General Intelligence
A system that could reason, learn, plan, and transfer knowledge across many domains.
Claim: not one workflow, but broad competence across tasks.
The jump from ANI to AGI is about breadth of competence, not just better output in one narrow workflow.
Fatih Kansoy
University of Oxford
00
Section 03
From Assistance to Automation
AI Spectrum · 3 of 3
ASI
Hypothetical
ASI
Artificial Super Intelligence
A theoretical system that would exceed the best human minds across most or all relevant domains.
Status: speculative, debated, and not something that exists today.
ASI is not the current reality. It is a speculative end-state in a very different debate.
Fatih Kansoy
University of Oxford
00
Section 03
From Assistance to Automation
AI-Assisted vs AI-Generated Papers
AI-Assisted
Human leads. AI helps.
A mature, human-led workflow where AI stays in a bounded supporting role.
The scholar still owns the argument, judgment, and final decisions.
vs
AIGPs
AI works. Human directs.
An experimental workflow where the system takes on substantial research labor.
The human behaves more like an advisor who critiques and redirects.
Main point: who is driving the project?
Fatih Kansoy
University of Oxford
08
Section 03
From Assistance to Automation
Can a robot do research?
Nature · 25 March 2026
A Nature paper says end-to-end AI research is now possible.
The paper presents The AI Scientist: a system that can generate ideas, write code, run experiments, draft the manuscript, and review its own output.
This is not a smarter chatbot. It is an agentic research pipeline.

25 March 2026
Lu et al. (2026), Towards end-to-end automation of AI research, Nature
nature.com/articles/s41586-026-10265-5
Lu et al. (2026), Towards end-to-end automation of AI research, Nature
nature.com/articles/s41586-026-10265-5
Fatih Kansoy
University of Oxford
09
Section 03
From Assistance to Automation
Automated research is a loop, not a prompt.
01
Idea Search
Find a question and check whether it is new.
02
Experiment
Edit code, run trials, and compare results.
03
Paper
Turn outputs into figures and write the manuscript.
04
Review
Score the draft and decide whether it is worth pushing.
The AI Scientist
One system
cycles through all four stages instead of answering a single prompt.
The point
The novelty is not better writing. It is a machine that can keep moving around the research loop.
Fatih Kansoy
University of Oxford
10
Section 03
From Assistance to Automation
Who does what?
What the AI does
Search. Build. Write.
Search
Generate candidate ideas and screen the literature for overlap.
Build
Edit the code, run trials, and convert outputs into figures.
Write
Draft the paper, add citations, and review the draft.
What the human still does
Choose. Filter. Approve.
Choose
Pick the domain template, starting scaffold, model, and constraints.
Filter
For the workshop test, humans manually filtered the most promising AI outputs at each stage.
Approve
Take responsibility for disclosure, withdrawal protocol, and submission.
Advisor logic, not chatbot logic.
Fatih Kansoy
University of Oxford
11
Section 03
From Assistance to Automation
What happened in the real test?
3
AI papers
entered workshop review
Blind
Human review
reviewers knew some submissions were AI-generated, but not which ones
1
Paper
cleared the workshop bar
Withdrawn
After review
the likely-accepted paper was pulled under the study protocol
Scores
6, 7, 6
6
Reviewer 1
7
Reviewer 2
6
Reviewer 3
6.33
Average
Top 45% of the 43 papers reviewed for the workshop.
Venue and result
At the I Can’t Believe It’s Not Better workshop at ICLR 2025, organizers said the strongest paper would likely have been accepted, but it was withdrawn by protocol because it was AI-generated. The accepted-style paper reported a negative result.
43 papers reviewed
70% workshop acceptance
32% ICLR main track
Fatih Kansoy
University of Oxford
12
Section 03
From Assistance to Automation
Why this matters beyond computer science
Research becomes pipeline
Work can be delegated.
Search, coding, drafting, and review can now be bundled and repeated inside one workflow.
Research turns into a process
Evaluation becomes scarce
Attention is the bottleneck.
If output gets cheaper, filtering, reading, and judgment become more valuable than before.
Review matters more
Institutions need labels
One norm is not enough.
AI-assisted work and AI-generated work cannot live under the same disclosure rules.
Journals need distinctions
For social scientists
Automation can change how research is organized long before it replaces theory.
Fatih Kansoy
University of Oxford
14
Section
04
04
From Chatbox
To Agents
To Agents
The chatbox ceiling • Skills, agents, pipelines • The agentic research workflow
Fatih Kansoy
University of Oxford
16
Section 04
From Chatbox to Agents
The Fundamental Shift
A Chatbot Answers.
An Agent Acts.
An Agent Acts.
Fatih Kansoy
University of Oxford
17
Section 04
From Chatbox to Agents
The Fundamental Shift · 1 of 2
A Chatbot Answers.
Chatbot (2022-2025)
01
Human
The human writes the prompt and manually decides the next step.
02
LLM
The model turns text into text.
03
Response
Useful output, but still a one-shot exchange.
No memory
No tools
No files
One-shot
Fatih Kansoy
University of Oxford
00
Section 04
From Chatbox to Agents
The Fundamental Shift · 2 of 2
An Agent Acts.
Agent (2026 →)
01
Plan
Sets the next task.
02
Act
Uses tools and files.
03
Verify
Checks whether the output works.
04
Reflect
Loops instead of stopping at one answer.
files
code
search
data
The change is not just better answers. It is memory, tools, multi-step execution, verification, and looped work.
Fatih Kansoy
University of Oxford
00
Section 04
From Chatbox to Agents
What Is a Skill?
A Skill is a plain-text instruction file that turns a general-purpose model into a specialist. It is not software. It is a repeatable protocol written in Markdown.
01
Trigger
When should the model activate this workflow? Which requests call it?
02
Modules
What ordered steps should it follow, and where should it pause to check the work?
03
References
Which checklists, style guides, examples, or files must be read before acting?
04
Constraints
What hard rules can never be broken?
Anatomy of a SKILL.md
name: academic-paper-review trigger: - "review my paper" - "write a referee report" modules: 1. Referee report 2. British English audit 3. LLM cliche detection 4. Style and repetition audit reads_before_acting: - british-english-guide.md - llm-cliche-list.md tools: [pdf_reader, semantic_search] checkpoints: after module 1, after module 3 constraints: never fabricate citations; British English only
Plain Markdown. One reusable protocol. The model reads it before it acts.
A Skill turns "I have a smart chatbot" into "I have a specialist that follows a reproducible workflow."
Fatih Kansoy
University of Oxford
17
Section 04
Skill File
The Skill Definition
SKILL.md
academic-paper-review · 4 modules · 2 checkpoints
--- name: academic-paper-review description: > Review economics and finance papers to publication-ready standard. Covers referee reports, British English, LLM cliche detection, and style auditing. trigger: - "review my paper" - "full review" - "referee report" - "check British English" - "check for LLM cliches" - "style audit" - "proofread" modules: 1. Referee Report Simulation 2. British English Audit 3. LLM Cliche Detection 4. Style & Repetition Audit reads_before_acting: - references/british-english-guide.md - references/llm-cliche-list.md tools: - semantic_scholar_api - pdf_reader inputs: - manuscript (.tex or .pdf) output: single consolidated report (LaTeX or Markdown) checkpoints: - after Module 1 — confirm major comments before continuing - after Module 3 — review severity before style audit constraints: - never fabricate citations, issues, or sources - british_english_only in all output text - no_em_dashes in suggested rewrites - verify_all_citations before including --- # Academic Paper Review A reusable, multi-module skill for reviewing economics and finance research papers. Calibrated to top-tier journals. ## Module 1: Referee Report Simulation Voice: Professor of economics serving as referee for a top journal. CHECKPOINT: Pause. Present major comments for human review. ## Module 2: British English Audit Read references/british-english-guide.md first. ## Module 3: LLM Cliche and AI-Voice Detection Read references/llm-cliche-list.md first. CHECKPOINT: Pause. Review severity before proceeding. ## Module 4: Vocabulary, Style and Repetition Audit - Overused words - Weak language - Passive voice - Repetition - Register ## Output Deliver one consolidated review document.
Scroll
Fatih Kansoy
University of Oxford
18
Section 04
From Chatbox to Agents
Academic Paper
Review Skill
Review Skill
One instruction launches the same review workflow every time. The model does not improvise from zero. It follows a fixed checking sequence.
01
Referee Report
Summarise the contribution, flag major weaknesses, and write the core review.
02
British English
Check spelling, punctuation, and consistency before the paper leaves your desk.
03
LLM Fingerprints
Catch generic phrasing, cliches, and stylistic tells that weaken the draft.
04
Style Audit
Check repetition, passive voice, and tonal drift across the manuscript.
One command
“Review my paper.”
A single request activates the full protocol.
The model loads references and starts the checks
The run
Read → Review → Audit → Merge
Four passes, one sequence, one structure.
One package comes back instead of scattered chat replies
The output
A structured review bundle
Referee report, language fixes, style warnings, and revision notes together.
The gain is not one clever review. It is consistent quality control you can run on every manuscript.
Fatih Kansoy
University of Oxford
18
Section 04
Reference File 1
Domain Knowledge File
british-english-guide.md
references/ · loaded before Module 2
# British English Guide for Academic Manuscripts Flag every American English spelling, punctuation, or usage in the manuscript. ## Spelling Rules Pattern American → British Examples ───────────────────────────────────────────────────────────── -ize → -ise Always convert analyse, characterise, standardise -or → -our Always convert behaviour, labour, colour, rigour -er → -re Convert for units centre, metre, theatre -ense → -ence Convert defence, licence (noun), offence -ing doubles Double the consonant modelling, signalling, labelled, travelled Other: grey (not gray), programme (not program, except software), judgement, ageing, sceptic, towards. ## Punctuation - Full stops and commas go outside quotation marks unless part of the quoted text. - Use single quotation marks; double only for nested quotes. ## Dates Write: 15 December 2015 (not December 15, 2015). ## Typical conversions analyze → analyse behavior → behaviour labor → labour organization → organisation modeling → modelling center → centre program → programme ## Output expected from the agent Return a table: | Location | American Form | British Correction | End with: "X Americanisms found across Y categories."
Scroll
Fatih Kansoy
University of Oxford
19
Section 04
From Chatbox to Agents
From Skill to Specialist
What Is an Agent?
An Agent is a model reading a Skill with a named role. Same underlying model, different instructions, different job. It can keep context, use tools, follow steps, and stop at checkpoints.
LLM + SKILL.md + Role = Agent
A chatbot waits for the next prompt. An agent keeps working through a plan.
Same Model, Different Jobs
Reviewer Agent
Reads the paper-review skill and produces a structured referee report.
Data Agent
Downloads, merges, validates, and documents data through a fixed workflow.
Econometrics Agent
Runs models, robustness checks, tables, and figures until diagnostics are satisfied.
Writer Agent
Drafts, revises, integrates citations, and compiles the manuscript in the right style.
A Skill is the protocol. An Agent is the worker that follows it. Multiple agents can share one model family and still do different jobs.
Fatih Kansoy
University of Oxford
19
Section 04
From Chatbox to Agents
The Building Blocks
Fatih Kansoy
University of Oxford
18
Section 04
From Chatbox to Agents
Building Blocks · 1 of 4
Foundation Model
General-purpose engine
LLM
This is the base model: broad capability, wide knowledge, but no narrow workflow or role by itself.
GPT
Claude
Llama
General-purpose rather than task-specific.
Useful across domains, but not yet organised for one repeatable job.
The model is the foundation, not the full workflow.
Fatih Kansoy
University of Oxford
00
Section 04
From Chatbox to Agents
Building Blocks · 2 of 4
Skill File
SKILL.md
A Skill is a plain-text protocol. It tells the model when to activate, what inputs to expect, what sequence to follow, how to verify, and what output to return.
Trigger: what request should call this workflow.
Inputs: which files, folders, or materials must be read.
Steps: the ordered procedure and checkpoints.
Verify: what has to be checked before finishing.
Output: the artifact the run should produce.
Skill = repeatable instructions, not software.
Fatih Kansoy
University of Oxford
00
Section 04
From Chatbox to Agents
Building Blocks · 3 of 4
Agent Role
Same LLM, different job
An agent is a model reading a Skill with a named role. The role changes what it pays attention to and how it behaves.
01
Methodology Reviewer
Checks design, statistics, and reproducibility.
02
Devil's Advocate
Attacks assumptions and finds weak logic.
03
Socratic Mentor
Challenges framing and forces clearer thinking.
04
Code Writer
Implements, debugs, runs, and iterates.
Fatih Kansoy
University of Oxford
00
Section 04
From Chatbox to Agents
Building Blocks · 4 of 4
Pipeline Orchestration
From agents to research
01
Research
Search and rank the literature.
02
Experiment
Write code and explore branches.
03
Write
Draft the manuscript and figures.
04
Verify
Check data, claims, and outputs.
05
Review
Score the draft and decide next actions.
06
Revise
Loop until the work clears review.
The human checkpoint remains after each stage. The pipeline lowers labour cost; it does not remove judgment.
LLM + SKILL.md = Agent
Agents + Pipeline = Research
Agents + Pipeline = Research
Fatih Kansoy
University of Oxford
00
Section 04
From Chatbox to Agents
How It Works
Orchestration: One LLM Conducts Many
Fatih Kansoy
University of Oxford
15
Section 04
From Chatbox to Agents
Orchestration · 1 of 2
One LLM Conducts
Orchestrator
`program.md`
The orchestrator does not do every job itself. It assigns the next task, checks each handoff, and decides whether the workflow should continue, branch, or stop.
01
Assign
Send the next job to the right specialist.
02
Check
Read what came back at each handoff.
03
Loop
Keep the cycle moving until review clears the work.
Fatih Kansoy
University of Oxford
00
Section 04
From Chatbox to Agents
Orchestration · 2 of 2
The Specialist Agents
Who does the work
01
Research Agent
Searches papers and tests novelty.
02
Experiment Agent
Writes code and explores branches.
03
Review Agent
Scores the draft and recommends the next decision.
04
Integrity Agent
Checks claims, evidence, and consistency.
05
Writing Agent
Turns outputs into figures, prose, and cited text.
The orchestrator sits in the middle. Each worker returns artifacts, and the loop continues until the human checkpoint says the work is credible enough to proceed.
Fatih Kansoy
University of Oxford
00
Section 04
The Research Pipeline
The Human's New Role
8 Stages, End-to-End
A workflow can now run across the full research cycle. What stays scarce is not execution alone. It is judgment at each handoff.
At every stage
AI executes
Collect, clean, code, draft, rerun, and package the work.
You judge
Choose the question, the design, the interpretation, and the claim.
AI Executes
You Judge
1 ·Ideation
Getting an idea
Maps the literature and proposes candidate questions.
Decide which question is worth pursuing.
2 ·Design & Feasibility
Empirical strategy · identification
Checks data availability and sketches feasible designs.
Choose the identification strategy and credibility standard.
3 ·Data Assembly
Collecting · cleaning · merging
Collects, cleans, merges, translates, and validates the corpus.
Set inclusion rules and measurement choices.
4 ·Core Analysis
Main specifications · models
Runs the main specifications, models, figures, and tables.
Judge which result is central and which is noise.
5 ·Robustness & Extensions
Alt specs · heterogeneity
Runs alternative specifications, heterogeneity cuts, and stress tests.
Decide which checks actually test the claim.
6 ·Writing
Drafting · tables & figures
Drafts prose, tables, figures, appendices, and code notes.
Shape the argument and strength of the claim.
7 ·Submission & Review
R&R · revising · seminars
Prepares response memos, revisions, seminar notes, and new checks.
Choose which criticisms to concede or resist.
8 ·Publication
Final acceptance · dissemination
Formats the final package, archive, replication files, and dissemination assets.
Stand behind the published claim and its meaning.
Fatih Kansoy
University of Oxford
20
Section
05
05
From Questions
To Workflows
To Workflows
Old questions become startable • API-scale research • Two examples
Fatih Kansoy
University of Oxford
22
Section 05
Question Space
What changes in practice
The question existed. The workflow did not.
The real shift
Some questions were never impossible.
They were just too expensive to start.
They were just too expensive to start.
The bottleneck was labour: collecting, cleaning, translating, reading, coding, checking, and repeating.
Too large
Whole archives can now be studied instead of tiny samples chosen only because humans could read them.
Too multilingual
Cross-country corpora stop being blocked by translation, formatting, and document heterogeneity.
Too repetitive
Classification, extraction, robustness checks, and draft revision can run in repeated loops, not one heroic pass.
Too costly to begin
Projects that sat for years because they demanded months of RA time can finally become startable.
AI does not supply the question. It lowers the fixed cost of asking it seriously.
Fatih Kansoy
University of Oxford
23
Section 05
Research Infrastructure
The practical shift
Leave the chat window.
Build a workflow.
Build a workflow.
2022 → 2026
Answering was the surprise.
Running the process is the real change.
Running the process is the real change.
Once the model sits behind an API, it can be called repeatedly, attached to files, and logged like any other research service. The important gain is repeatability.
Chatbox
API workflow
Unit of work
One exchangeA person asks, waits, and manually moves to the next step.
Whole corpusThe model can be called across thousands of documents or tasks.
Context
Short sessionContext is fragile and easily lost across tasks and files.
Files and logsFolders, prompts, outputs, and budgets become part of the record.
Labour
Copy-pasteThe researcher manually bridges collection, analysis, and drafting.
Repeated jobsCollection, reading, coding, and checking can be scripted and rerun.
Output
A responseUseful text, but weak as a reusable research artifact.
Research objectsDatasets, code, tables, figures, notes, and draft sections.
Fatih Kansoy
University of Oxford
24
Section 05
Research Workflow
General pattern
A serious project becomes a loop.
One prompt is not the unit of work. Research-grade use means building a corpus, making it comparable, analysing it, and then forcing another pass.
01
Build corpus
Pull speeches, tweets, PDFs, minutes, and metadata from archives, APIs, and websites.
OutputRaw archive
02
Make comparable
Clean, deduplicate, translate, and structure the material into something one design can actually use.
OutputResearch dataset
03
Read at scale
Classify, extract, label, and compare patterns across the full corpus rather than a hand-coded slice.
OutputMachine-readable evidence
04
Estimate
Run code, event studies, regressions, robustness checks, and produce tables and figures.
OutputResults
05
Review
Challenge claims, inspect code, rewrite weak passages, and make the argument survive another round.
OutputRevised draft
AI handles execution collect, clean, translate, classify, code, plot, and draft inside the loop.
The researcher stays central choose the question, the identification strategy, the interpretation, and the standard of proof.
Fatih Kansoy
University of Oxford
25
Section 05
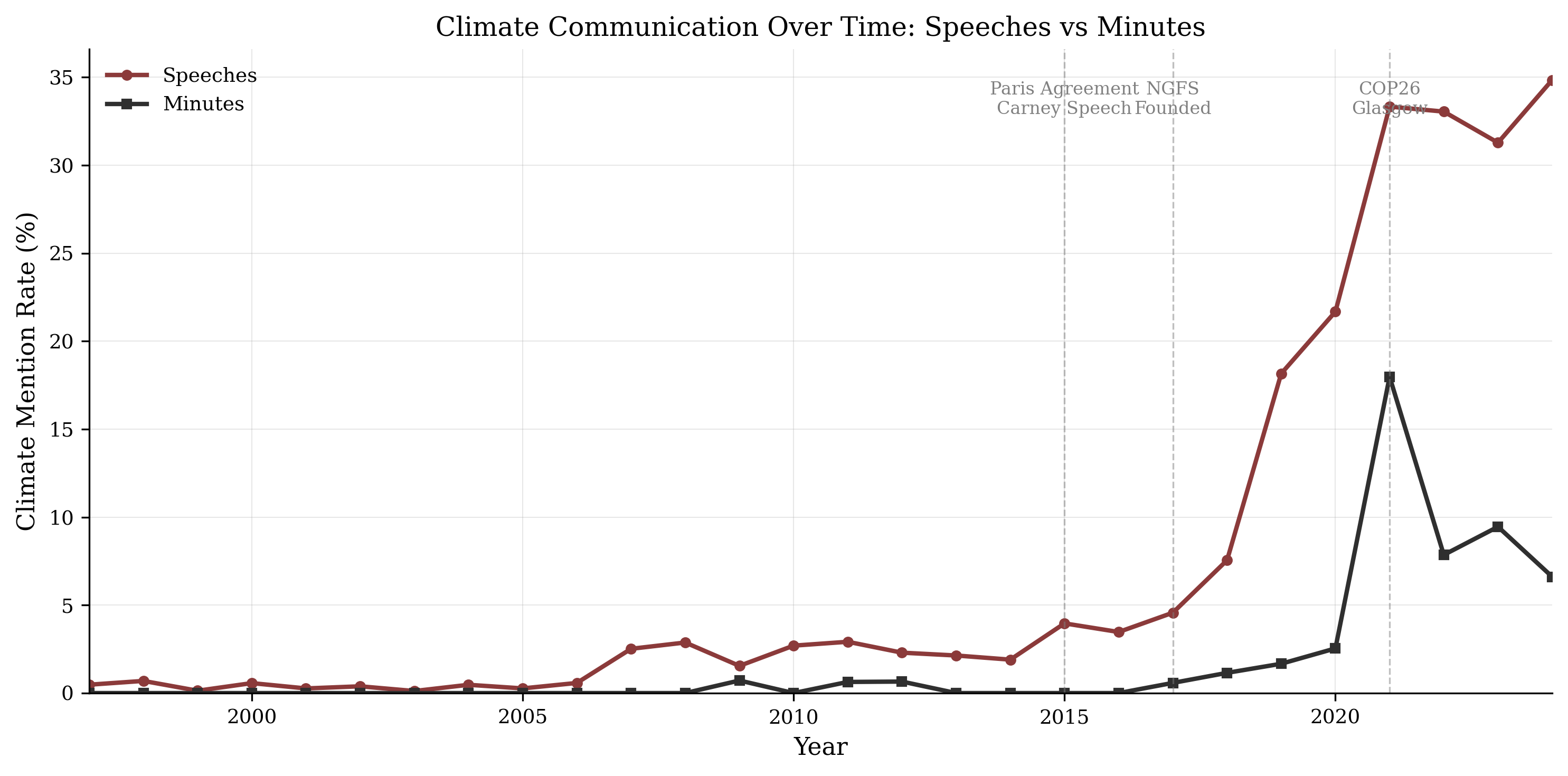
Climate & Central Banking
Example 1
Do central banks take climate seriously?
A long-standing question became tractable.
The hard part was not the idea. It was joining speeches, minutes, languages, and verification into one comparable corpus. The execution barrier finally fell.
Speeches
37,790
132 central banks
Minutes
3,602
26 institutions
Languages
14
translated and compared
Workflow
Collect archives, translate 14 languages, verify real climate mentions, then estimate the gap between public speeches and private deliberation.
Fatih Kansoy
University of Oxford
26
Section 05
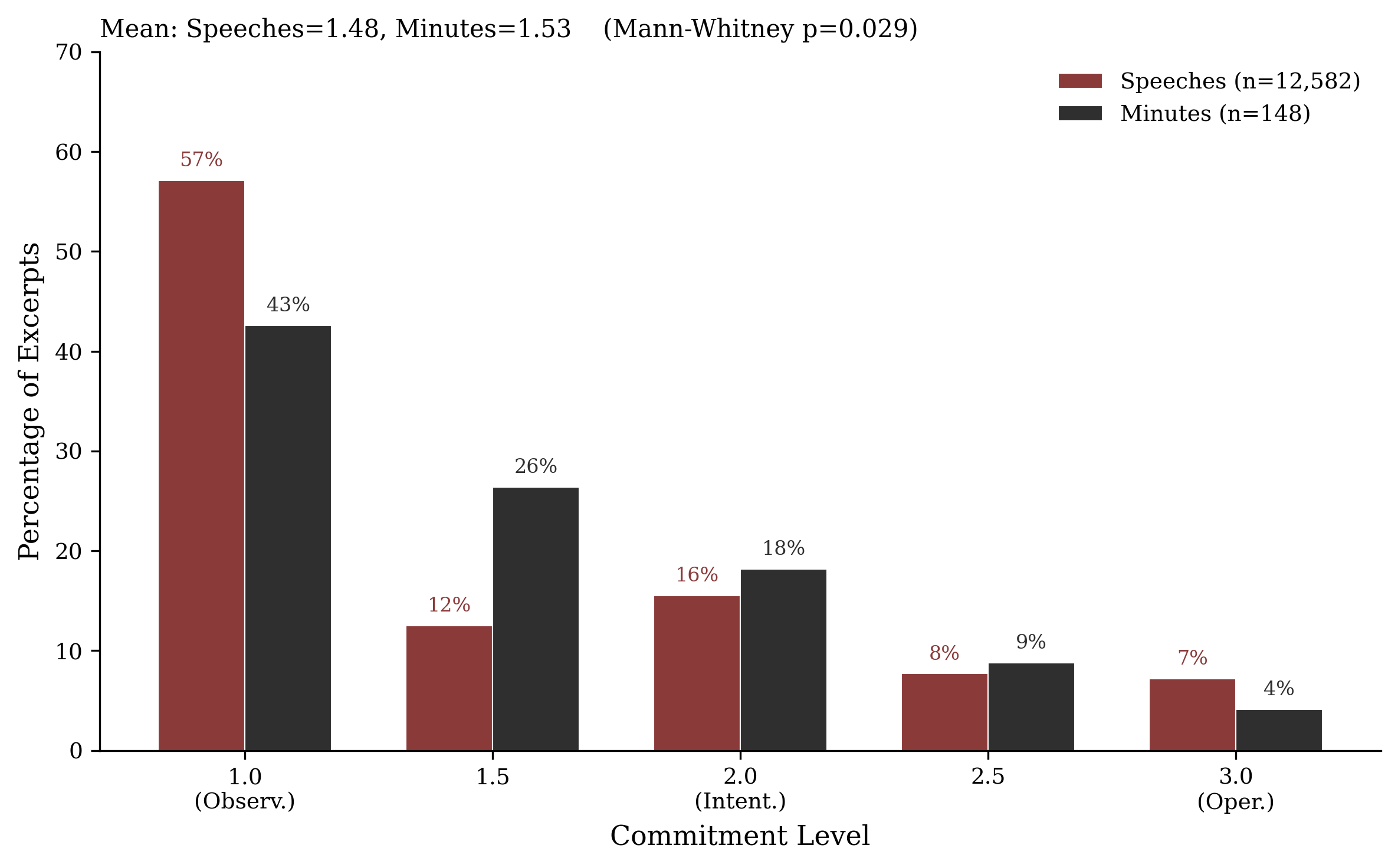
Bank of England & Twitter
Example 2
One Twitter archive became several papers.
The archive was there. The lab was not.
With LLM reading and faster coding loops, the same corpus could support questions about attention, format, timing, and communication design rather than simple description.
Official tweets
9,810
Bank of England posts
Public tweets
3.1m
wider conversation archive
Window
2011-2022
one reusable data build
What the workflow changed
01
Build the archive of official tweets, public tweets, metadata, and event windows.
02
Read the full record with LLMs instead of manually coding a small slice.
03
Move to empirical design with event studies, Poisson models, and communication-architecture tests.
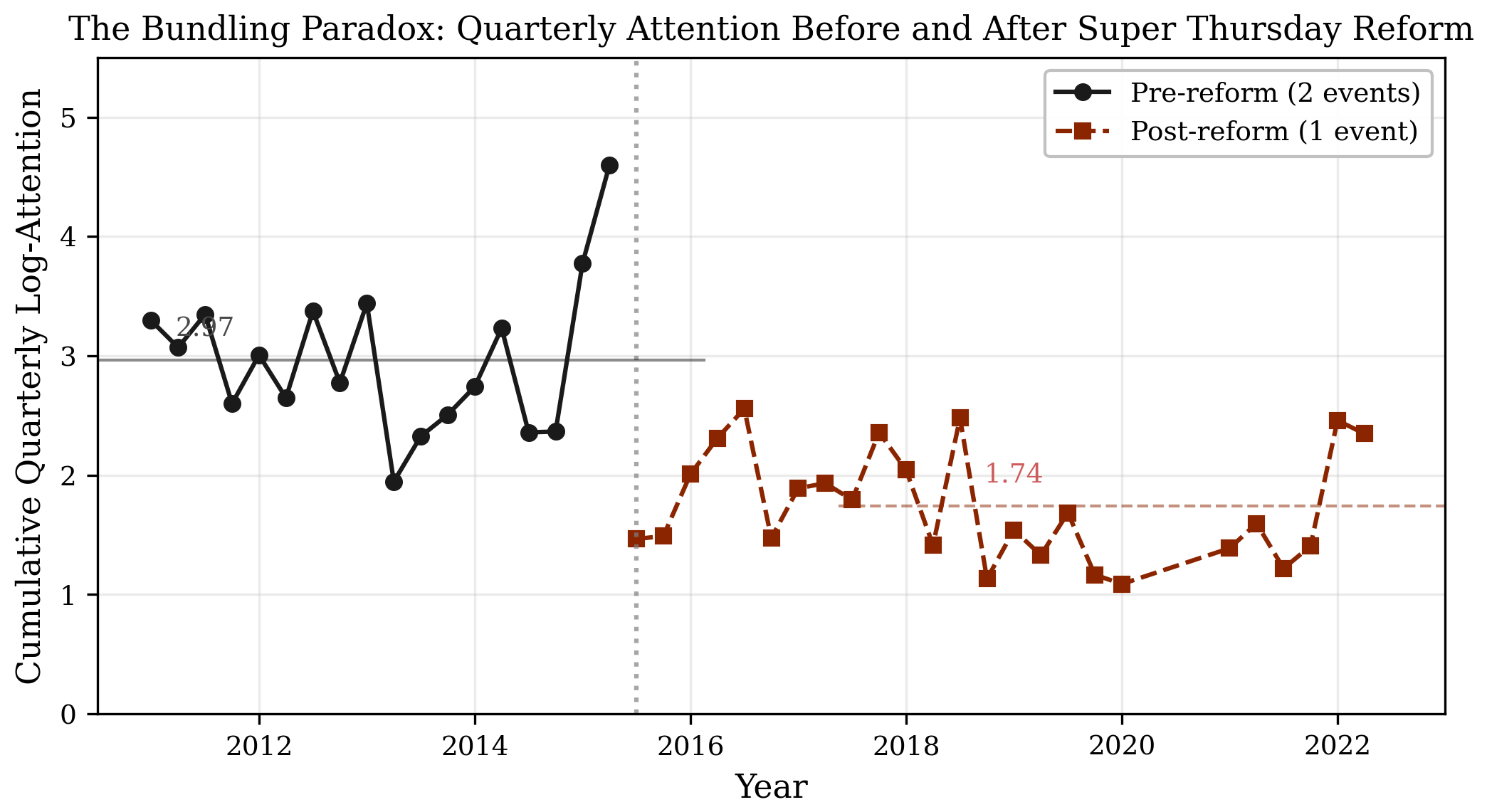
Format
+181%
photo tweets; videos add +159%
Timing
+150%
attention premium on MPC days
Design
Shifted
bundling raised event-day salience but changed cumulative attention across the quarter
Fatih Kansoy
University of Oxford
27
Section
06
06
Practice:
From Question
to Paper
From Question
to Paper
One research question. Three ways to do it.
Fatih Kansoy
University of Oxford
28
Section 06
Research Design
Case Paper
Does wealth composition shape how you live, work, and vote?
Rising house prices pushed young adults into portfolios dominated by illiquid housing wealth. The question is whether this compositional shift changes behaviour even when total wealth stays similar.
Profile A
House rich,
cash poor
cash poor
Trapped by illiquidity. Harder to move, retrain, or absorb shocks.
$500k
equity
$10k
liquid
Profile B
Balanced,
strong liquidity
strong liquidity
Same wealth class. Very different room to act and adjust.
$250k
equity
$260k
liquid
Data, all public
PSID
Wealth decomposition
psidonline.isr.umich.edu
CPS
Labour supply, income
census.gov/cps
CEX
Consumption, savings
bls.gov/cex
ANES
Political preferences
electionstudies.org
ACS
Housing, demographics
data.census.gov
FRED
FHFA HPI + mortgage rates
fred.stlouisfed.org
Six datasets, all free. The bottleneck was not access. It was the time and skill required to merge, model, and interpret them.
Fatih Kansoy
University of Oxford
29
Section 06
Three Approaches
Same Question. Three Workflows.
1 · Traditional
The Old Way
Formulate the question with colleagues
Check the data and learn the method
Do you have the Stata or R skills?
Merge six datasets and code the design
Interpret, write, and submit
Bottleneck: researcher time
6–18 months
2 · Chatbot
LLM at Each Step
Ask ChatGPT or Claude at each stage
Copy-paste code, run it, paste errors back
Context resets mid-analysis
Dozens of chats, no artifact chain
Hallucinated variables and fragile memory
Bottleneck: orchestration by hand
2–4 months
3 · Agentic
End-to-End System
Write a design file with question and strategy
Agent downloads, cleans, merges, and models
Runs robustness, figures, tables, and draft
Pauses after each stage for you
Revises, reruns, and compiles into artifacts
Bottleneck: judgment, not execution
1–3 weeks
The real shift: the agentic workflow preserves context, files, tools, checkpoints, and outputs across the entire research cycle.
Fatih Kansoy
University of Oxford
30
Section 06
Orchestration
The Pipeline for This Paper
01
Design Doc
Research question
Identification strategy
Data sources and URLs
Variable definitions
You write this
02
Data + Analysis
Download PSID, CPS, ACS, and FRED
Clean, merge, and structure the panel
Build IV, run first stage, check strength
Robustness checks and falsification tests
Agent iterates
03
Manuscript
Figures and tables
Draft each section
Citations and literature scaffolding
LaTeX and replication package
Draft, not final
04
Review
Is the instrument credible?
Does exclusion restriction hold?
Is the effect economically meaningful?
This part cannot be automated
You judge this
Phases 2 and 3 are cheap to automate. Phases 1 and 4 are where training, taste, and scientific judgment still matter most.
Fatih Kansoy
University of Oxford
31
Section 06
The Actual Prompt
End-to-End Agentic Research
The Master Prompt
361 lines · 7 stages · Claude Code / Codex
════════════════════════════════════════════════════════════════════ MASTER RESEARCH PROMPT — WEALTH COMPOSITION AND BEHAVIOUR ════════════════════════════════════════════════════════════════════ Use this prompt with Claude Code, OpenAI Codex, or another agentic coding tool. Pause after each numbered stage for human review before proceeding. You are a research agent building an economics paper from scratch. The project produces a complete, submission-ready manuscript with replication package. CRITICAL RULES (apply to every stage): - British English throughout. No American spellings. - No LLM cliches: no "delve", "crucial", "notably", "it is worth noting", "sheds light", "in the realm of", "a growing body of literature". - No long em dashes. Use commas, semicolons, or full stops. - Every citation must be real, verified, and correctly attributed. - Every number in the paper must be traceable to a specific data operation. - Figures: seaborn, colours = brickred (#9c302b), black (#171411), grey (#9f907b), navy (#2d5a8e). No annotations, no gridlines, no chartjunk. - Tables: booktabs style, no vertical rules, minimal horizontal rules. - Writing: argumentative, paragraph-based, no bullet points in the paper. - Paper length: 5,000-7,000 words (excluding references and appendix). - LaTeX: use natbib with aer.bst or similar author-year style. ════════════════════════════════════════════════════════════════════ STAGE 0 — PROJECT SETUP ════════════════════════════════════════════════════════════════════ Create the folder structure: wealth_composition/ ├── paper/ ├── replication/ ├── scripts/ ├── data/raw/ and data/derived/ ├── analysis/ ├── notes/ ├── README.md └── NEXT.md Write a one-paragraph README and set NEXT.md to "Stage 1: Data collection." ════════════════════════════════════════════════════════════════════ STAGE 1 — DATA COLLECTION ════════════════════════════════════════════════════════════════════ Download public datasets and log every URL, access date, and file hash: 1. PSID — https://psidonline.isr.umich.edu 2. CPS ASEC — https://www.census.gov/programs-surveys/cps.html 3. CEX — https://www.bls.gov/cex/ 4. ANES / CCES — https://electionstudies.org 5. ACS — https://data.census.gov 6. FRED — https://fred.stlouisfed.org Track household wealth, home equity, labour supply, expenditure, politics, home value, mortgage status, FHFA HPI, mortgage rates, and CPI deflators. After downloading, update NEXT.md: "Stage 2: Data cleaning and merge." PAUSE. Wait for human review of downloaded data before proceeding. ════════════════════════════════════════════════════════════════════ STAGE 2 — DATA CLEANING AND VARIABLE CONSTRUCTION ════════════════════════════════════════════════════════════════════ Write separate cleaning scripts: 01_clean_psid.py 02_clean_cps.py 03_clean_fred.py 04_clean_acs.py 05_clean_cex.py 06_clean_anes.py Each script: - Reads from data/raw/ - Writes cleaned parquet to data/derived/ - Prints N, means, and missingness - Deflates all money variables to 2020 dollars Construct key variables: - total_wealth - home_equity - liquid_wealth - housing_share = home_equity / total_wealth Build the FRED exposure instrument: - FHFA HPI by state and year - annual mortgage rate - entry_exposure = HPI(s,t*) × rate(t*) Write 07_merge_panels.py: - Merge PSID with the instrument on state × cohort - Create the analysis sample: ages 25-40, positive total wealth - Export analysis_panel.parquet Also merge CPS, CEX, and ANES panels with the same state × cohort logic. Print final sample sizes and update NEXT.md: "Stage 3: Descriptive analysis." PAUSE. Wait for human review of cleaning scripts and sample sizes. ════════════════════════════════════════════════════════════════════ STAGE 3 — DESCRIPTIVE ANALYSIS AND FIGURES ════════════════════════════════════════════════════════════════════ Write 08_descriptives.py and save all outputs to paper/figures/ and paper/tables/. Produce: - Figure 1: housing share of wealth by birth cohort - Figure 2: distribution of housing share - Table 1: summary statistics by tercile - Figure 3: first stage, entry exposure predicts housing share Update NEXT.md: "Stage 4: Estimation." PAUSE. Wait for human review of figures and descriptives. ════════════════════════════════════════════════════════════════════ STAGE 4 — ESTIMATION ════════════════════════════════════════════════════════════════════ Write 09_estimation.py. Use linearmodels or statsmodels for IV and cluster by state. Main tables: - Table 2: housing share and labour supply - Table 3: first-stage diagnostics - Table 4: housing share and consumption - Table 5: housing share and political preferences - Table 6: robustness and placebo tests Run OLS and 2SLS, report F-statistics, and save all tables as .tex files. Update NEXT.md: "Stage 5: Paper writing." PAUSE. Wait for human review of all estimation results. ════════════════════════════════════════════════════════════════════ STAGE 5 — PAPER WRITING ════════════════════════════════════════════════════════════════════ Write paper/main.tex using natbib, booktabs, graphicx, amsmath, geometry, setspace, and hyperref. Title: "Portfolio Composition and Behaviour: Housing Equity, Labour Supply, Consumption, and Political Preferences Among Young Adults" Sections: 1. Introduction 2. Related Literature 3. Data and Measurement 4. Empirical Strategy 5. Results 6. Discussion and Conclusion WRITING CONSTRAINTS: - British English only - No bullet points in the paper - No fake citations - Reference every table and figure before it appears - 40-60 real references PAUSE. Wait for human review of the full draft. ════════════════════════════════════════════════════════════════════ STAGE 6 — COMPILE, VERIFY, AND PACKAGE ════════════════════════════════════════════════════════════════════ Compile the paper and fix all LaTeX errors. Verification checklist: - Trace every number to a table or script line - Check every citation in text appears in bibliography.bib - Confirm every figure and table file exists - Confirm the word count is between 5,000 and 7,000 Build the replication package: - copy scripts to replication/code/ - copy datasets to replication/data/ - copy figures and tables to replication/output/ - write replication/README.md Update NEXT.md: "Complete. Ready for human review." PAUSE. Present compiled PDF and verification report for final review. ════════════════════════════════════════════════════════════════════ END OF PROMPT ════════════════════════════════════════════════════════════════════
Scroll to read full prompt
Fatih Kansoy
University of Oxford
32
Section 06
Live Demo Result
From One Prompt
What the Agent
Actually Built
Actually Built
6
Datasets merged
28.5M
Rows cleaned
26,936
Analysis sample
21
Python scripts
7 + 6
Figures + tables
5,297
Words in paper
The Full Output
Data Pipeline
Downloaded PSID, CPS, ACS, FRED, and related files. Cleaned derived tables, built the state-by-cohort instrument, and merged the analysis panels.
Econometrics
Ran OLS and 2SLS, checked first-stage strength, produced labour, consumption, political, and robustness results.
Manuscript
Drafted the LaTeX paper, generated sections, figures, tables, and tied the numbers back to scripts.
Verification
Tracked quantitative claims, checked citations, and verified that reported outputs matched the actual artifacts.
One research prompt produced a full artifact chain. No manual data cleaning. No copy-paste coding. No manual formatting.
Fatih Kansoy
University of Oxford
32
Section 06
The Lesson
What the Paper Found
Strong Description.
Weak Identification.
Weak Identification.
The descriptive patterns are strong: balance-sheet composition clearly separates households that look similar in total wealth.
The paper documents large differences in liquidity, labour supply, and downstream outcomes across composition profiles.
But the instrument is weak. The first stage does not justify a strong causal claim.
Robustness checks show the design is fragile. The execution is solid, but the identification still fails.
The substantive lesson is not that the agent failed. It is that good execution cannot rescue a weak design.
The Teaching Point
The Agent Built
the Telescope.
the Telescope.
What the agent did
Collected, cleaned, merged, estimated, wrote, and verified. It executed the research design with speed and consistency.
What the agent could not do
Know in advance whether the instrument would be persuasive. That requires theory, taste, and judgment about the data-generating process.
Why this is the real lesson
A positive result would show that the agent can execute. A negative result shows something deeper: judgment remains the binding constraint.
Execution depreciates. The harder and more valuable part is deciding whether the result deserves belief.
Fatih Kansoy
University of Oxford
33
Section 06
The Lesson
What Depreciates.
What Appreciates.
What Appreciates.
Depreciates ↓
Writing Stata, R, or Python line by line
Cleaning and merging datasets manually
Implementing a known estimator
Formatting the draft for journal style
Producing standard tables and figures
Appreciates ↑
Knowing which questions matter
Taste for a credible research design
Recognising when data is misleading you
Judging whether results are meaningful
Deep institutional and substantive knowledge
The takeaway
Execution gets cheaper. Judgment does not.
Fatih Kansoy
University of Oxford
32
Closing
The Research Crisis
Nature 2023
Papers and patents are becoming less disruptive.
Park, Leahey, and Funk study 45 million papers and 3.9 million patents. Across fields, the disruption index falls sharply over time: science is producing more, but breaking less.
45M
Papers
analysed across the sciences
3.9M
Patents
tracked over time
92-100%
Decline
in disruption across fields
This is the backdrop for everything else in the talk. AI arrives in a world where execution scales quickly, but truly novel ideas are already getting harder to produce.
Park, Leahey & Funk (2023) · Nature
Papers and patents are becoming less disruptive over time
Execution is getting easier. Novel ideas are getting harder.
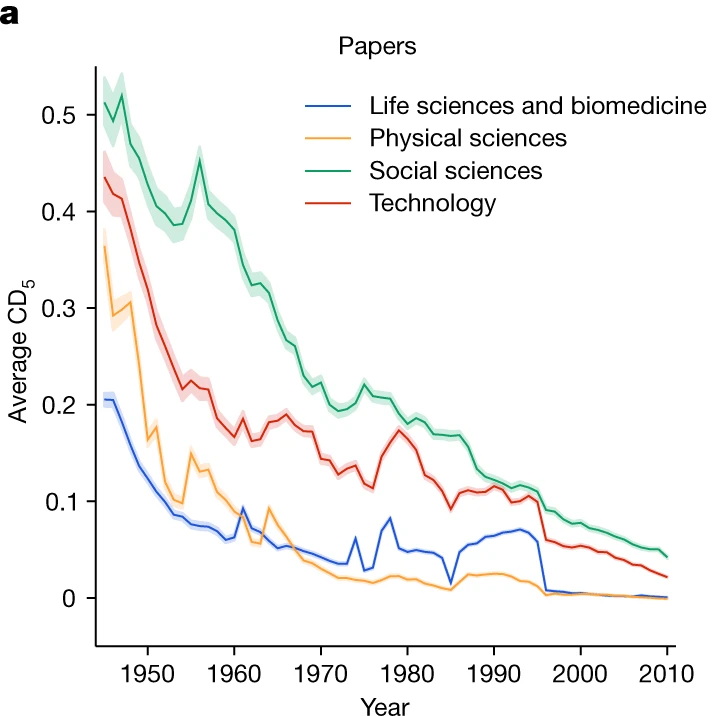
Papers
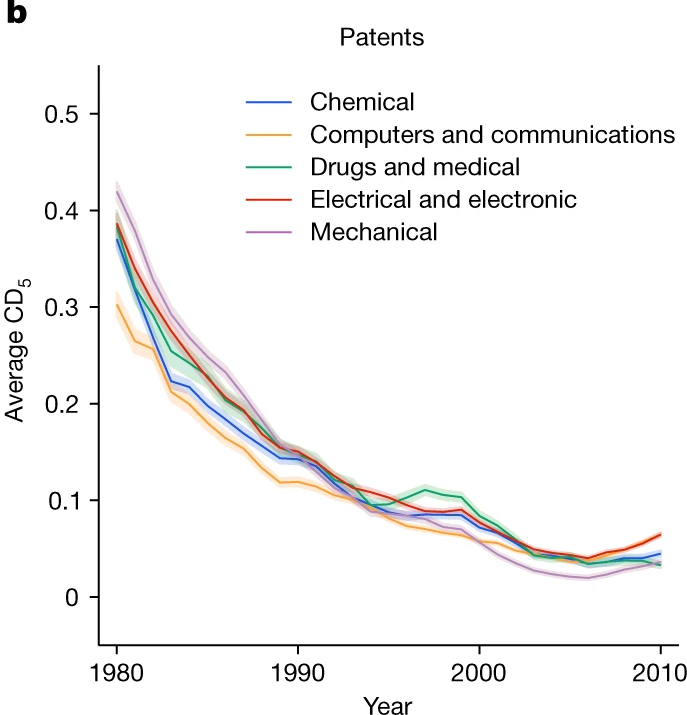
Patents
Use the arrows or dots to switch between the paper-side and patent-side figures in the same frame.
Fatih Kansoy
University of Oxford
33
Closing
The Scarce Input
The Scarce Input
Information became abundant.
Execution is becoming abundant.
Execution is becoming abundant.
The novel question
remains scarce.
remains scarce.
AI lowers the cost of doing. It does not decide what is worth doing.
Fatih Kansoy
University of Oxford
19